

HAMLET: How About Machine Learning Enhancing Theses?
By Andromeda Yelton, Berkman Klein Center for Internet & Society at Harvard.edu
About hamlet
Hamlet uses machine learning to power experimental, exploratory interfaces to the MIT thesis collection.
It is extremely in alpha right now. Some of the interfaces are not yet written; there has been no UX consideration; the server may break at any time without warning. Check back to see how hamlet grows! You can send feedback to Andromeda Yelton.
How it works
Hamlet is based on paragraph vectors (Le and Mikolov (2014)), which extend the word2vec algorithm (Wikipedia; Mikolov et al. (2013)). If you enjoy mathematical explanations, the original papers are quite readable and interesting; if you would prefer a more library-centric explanation, read on.
In traditional library cataloging, documents are assigned one or more subject headers (such as Space flight — Fiction). You can find similar documents by looking for other documents with the same subject headers.
We usually think of subject headers as a list — “here are the five subjects assigned to this book”. However, we might instead think of them as a vector: “for each of the millions of possible subject headers, assign them a Boolean depending on whether they describe this book”.
Once you’ve got a vector rather than a list, though, there’s no reason to restrict yourself to Booleans. Documents might be very much about some topics, and somewhat about others, a tiny bit about yet others, and not at all about the rest. For instance, one might end up with the following graph, situating science fiction books according to how much they’re about gender and spaceships (tiny spoilers ahoy):
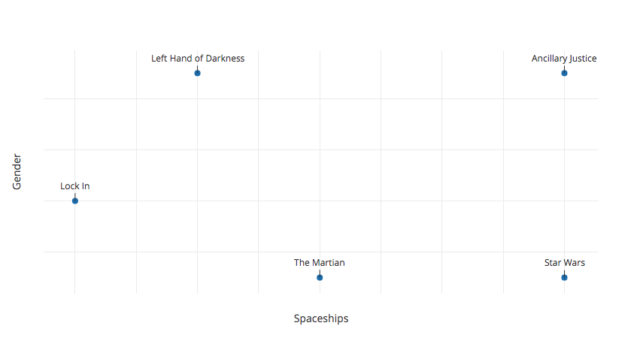
Ancillary Justice is very much about gender and also very much about spaceships. Left Hand of Darkness is also a lot about gender, but only a little bit (but more than zero) about spaceships. The Martian has basically no gender at all, and some spaceships, but not nearly as many as Mark Watney would like. Et cetera.
You can imagine there might be more than two concepts, and therefore instead of a two-dimensional graph you could have a three-dimensional space (or four-dimensional, or four-hundred-dimensional…) Each document has a vector, with one number per concept, that pinpoints its coordinates in that space.
Thinking about documents in this way gives you lots of interesting options. For instance, you can ask questions like, “Is Ancillary Justice more like The Martian or like Star Wars?” And you can get an answer that’s literally a number — you can compare the distance between each book. You can also ask questions like “What do you get if you take Star Wars and add more gender?” or “If you start with Ancillary Justice and subtract out the stuff that’s also in Left Hand of Darkness, what book is most like the parts that remain?” Because these questions all have mathematical meaning, computers can calculate their answers.
Doc2Vec basically reads in documents and generates spaces like the one above, with two important exceptions:
- There are potentially hundreds of dimensions in the concept space, not just two (as on the graph above).
- Doc2Vec figures out the concept space as it goes, and it likely doesn’t map to meaningful human concepts like “gender” or “spaceships”.
So imagine a space that’s hundreds of dimensions and doesn’t have labels – but again, each document is a point in that space, and we can ask questions that are both semantically interesting and mathematically meaningful. “Which of these documents are most similar?” “If we started at one document and added or subtracted others, where would we end up?”
The hamlet back end is a neural net that learned a concept space from the MIT thesis collection. The front end is where we ask questions.
Who made this

Andromeda Yelton is the lead for hamlet. She’s a software engineer at the Berkman Klein Center (formerly at the MIT Libraries) and the 2017-2018 President of the Library & Information Technology Association. She wrote most of the code: the machine learning; processing pipeline to extract fulltext and metadata from dSpace; and the front and back ends of the Django app.
Thanks also go to the following:
? Frances Botsford, who wrote the (modular, readable, wondrous) style system;
?️ Andy Dorner, who set up the AWS pipeline;
? Mike Graves, who improved the file upload process and researched citation processing options;
? Helen Bailey, whose dSpace extraction work I adapted, and who is hamlet’s once and future data visualization wonk.
?️ All the catalogers and techies who have added theses to dSpace and kept it going over the years.
The tech stack
Hamlet is a Django app, backed by a postgres database and a neural net trained using gensim on the fulltext of approximately 43,000 MIT graduate theses living in dSpace@MIT.
Its code lives on GitHub and it’s hosted on AWS.
This article originally published at THE BUZZ – Berkman Klein Center for Internet & Society at Harvard University on Sep 27, 2018.
No Comments
