

Alphabet’s DeepMind Makes a Key Advance in Computer Vision
Alphabet’s DeepMind neural networks can grasp a three-dimensional scene from just a handful of two-dimensional snapshots
By Philip Ross
Researchers at Alphabet’s DeepMind today described a method that they say can construct a three-dimensional layout from just a handful of two-dimensional snapshots.
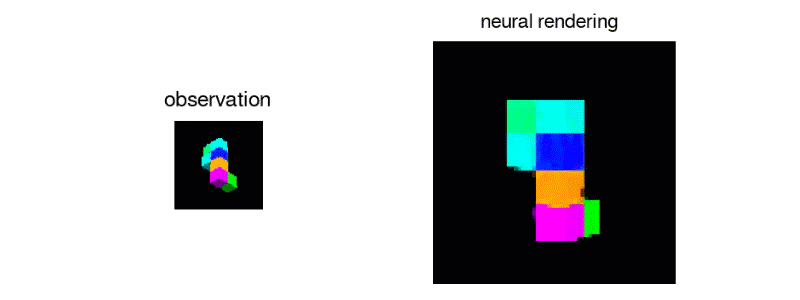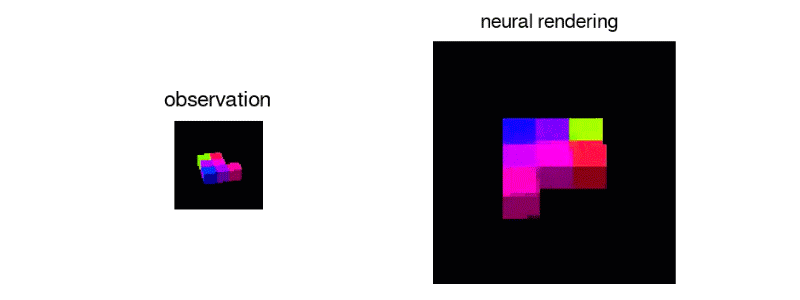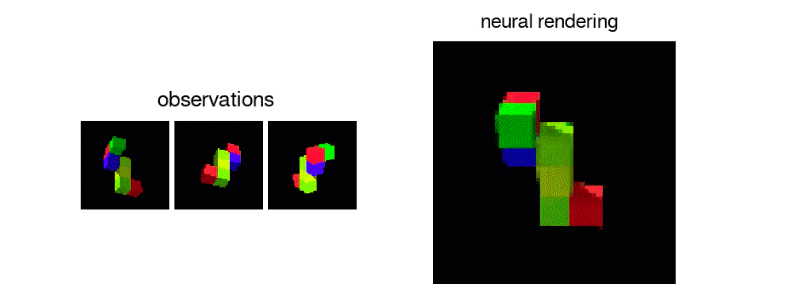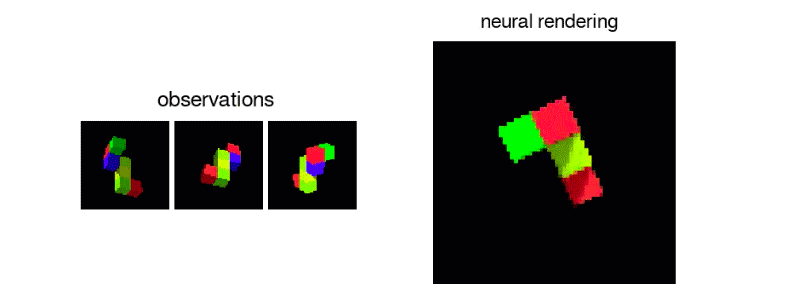
GQN agent performing the Shepard Metzler object rotation task. Gif: DeepMind
So far the method, based on deep neural networks, has been confined to virtual environments, they write in Science magazine. Natural environments are still too hard for current algorithms and hardware to handle.
The article doesn’t speculate on commercial applications, and the authors weren’t available for interview. That gives me license to speculate: The new method might be useful for any surveillance system that has to reconstruct a crime from a few snapshots. Self-driving cars and household robots would also seem likely beneficiaries of the technique.
What’s key is that the system learns a lot from very little—in these experiments it never got more than five snapshots to work with. And, the researchers write, it does the job by observation alone, without anyone having to first label the objects and “without any prior specification of the laws of perspective, occlusion, or lighting.”
The researchers use two neural networks, a representation network and a generation network. This would seem to correspond to the “generator” and the “discriminator” networks described in DeepMind’s 2016 paper on AlphaGo, the Go-playing machine.
The representation network reduces perceived objects to a very simplified abstraction, leaving it to the generation network to fill in the details. The researchers give, as an example, a robot arm that can be abstracted as a simple articulation, with several joints, which is then constructed using data on form, color and so forth.
By manipulating the abstraction first and filling in details later, the system can work much faster than rendering systems that attempt to manipulate huge sets of three-dimensionally related points. The researchers add that the division of labor also makes the method much better at representing soft objects, like animals and vegetables.
Alphabet’s DeepMind, based in London, is still best known for its out-of-the-blue advance in cracking the game of Go. That problem, long seen as a Holy Grail of computing, yielded in 2016 when the company’s AlphaGo program beat one of the world’s best players. Last year DeepMind built a second machine that utterly crushed the first one after mere weeks of self-teaching.
Alphabet, the umbrella corporation that owns DeepMind, gets almost all its revenue from Google, and it has been pushing to generate new streams of income from its other units. DeepMind did discover a way to save substantial energy in Google’s server farms, and earlier this year a method for improving a text-to-speech product went to market.
But if the company can extend its achievement in machine vision to real-life optical feeds, it just might bring the wave of applications Alphabet is hoping for. A good deal of what’s called thinking can be put down to sheer perception, and perception itself is harder for computers than is generally understood.
There is a standard psychological test of the human ability to mentally rotate objects that uses geometric figures known as Shepard-Metzler Objects. In a video supplied by DeepMind, the neural nets classify these objects as one of two kinds: Either they are versions of a template that’s been rotated in one or more planes or they are mirror images of that template. The DeepMind networks do the job well. Not all people can say the same thing.
It’s the human ability to do this sort of thing, as well as to figure out what must lie behind a barrier to vision—like a lock of hair or a branch of a tree—that explains why we can navigate complex environments so well. A human being knows, from simple experience of the world, that a person who is in the sitting position is almost always to be found on a chair (and only very rarely on thin air, as circus mimes might do).
Such common-sense knowledge has been unheard-of in robots. So far.
This article first published at IEEE Spectrum on June 14, 2018.
No Comments
